In this post, I'm going to explore a disk image which contains a FAT32 partition completely using a hex editor. This exploration provides an important insight on how FAT file system works. The disk image I'm using for this is a 100MB long file which can be download from
here. SHA1 hash value of the file is as follows.
d665dd4454f9b7fc91852d1ac8eb01a8f42ed6be
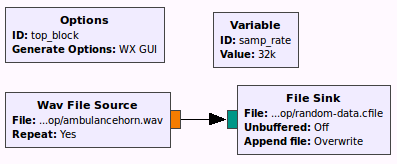
(1) First of all, we open this disk image using Okteta. Here's the first 512 bytes which is the first sector of the disk looks like. That means this is the Master Boot Record (MBR). We can see distinguishable features of the MBR here. The very first thing to spot is that the last two bytes located at the offset 0x01FE of this sector contains the value 0x55AA.
 |
| First sector of the image which is the MBR |
(2) In order to find the files stored in this disk image, we need to first locate the FAT partition. To locate FAT partition we have to find it by reading the partition table inside MBR properly. By looking at the structure of the MBR, we can see that partition table takes 64 bytes long area at the end of the partition right before the last two bytes signature. To make our life easier, let's just copy partition table and paste into a new tab in Okteta.
 |
| Partition table which is 64 bytes long |
(3) Once again, a glance at the structure of a partition table entry tells us that an entry in the table is 16 bytes long and the whole table is 64 bytes long. That means it can accommodate up to 4 partition entries. Empty partition entries are filled with zeros. Now, when we look at the partition table that we just extracted from our image, we can see that there's only one partition entry there. Following is that entry.
00202100 0BBE320C 00080000 00180300
(4) Let's start interpreting this partition entry. The very first byte in this entry tells us whether this partition is bootable or not. That means whether this partition contains an operating system or not. The first byte contains 0x00. That means, no this is not a bootable partition.
(5) Another useful information is what type of file system is available on this partition. That information is available in the offset 0x04 location in the partition entry. That value is 0x0B as you can see. Our reference document tells us that this value means, our partition is a FAT32 partition. Great! We know about FAT file system. So we will be able to explore this partition.
(6) Next question that arises is where is this FAT32 partition in the disk image? How to locate it? Again our reference document tells us that the offset 0x08 of the partition entry contains 4 bytes which specify the starting sector of this partition. When you look at the partition entry, you can see that this value is 00 08 00 00. So, this value represents the starting sector of the FAT32 partition. We need to interpret this number carefully. This is a number stored in little-endian format. That means, the last byte is the most significant byte. We have to reverse the order of these bytes before interpreting.
The number you get once you revert it from little-endian format is 00 00 08 00. Let's use the calculator to convert this hexadecimal number to decimal. The decimal value is 2048. That means This FAT32 partition begins at the sector number 2048. Let's go there and see this partition.
But, wait! Our hex editor shows offsets in bytes, not in sector numbers. So, we need to find the byte offset of this sector number 2048. We can easily do that by multiplying 2048 by 512 because there are 512 bytes in a sector.
2048 x 512 = 1048576
Again, we have to convert this decimal byte offset 1048576 into hexadecimal before going there. Ask help from the calculator for that too.
1048576 (decimal) = 100000 (hexadecimal)
Now, 100000 is the byte offset in hexadecimal where you can find the FAT32 partition.
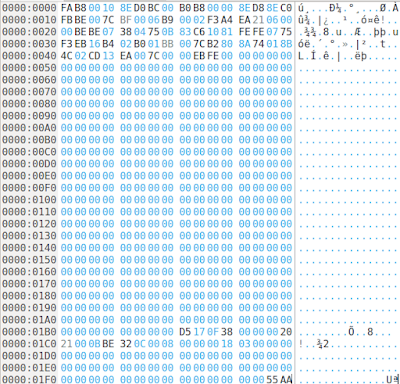
(7) Instead of scrolling down to find the above offset, we have an easy way in Okteta editor. You can go to Edit menu and select Go to Offset... option. Then, at the bottom of the Okteta window, you get a text field where you can specify where you want to go. Put 100000 there and hit Enter.
 |
| First sector of the FAT partition which is the boot sector. |
Now, we are at the FAT32 partition. It's time to take the reference document which has FAT32 related data structures to your hand. We need it from here onwards.
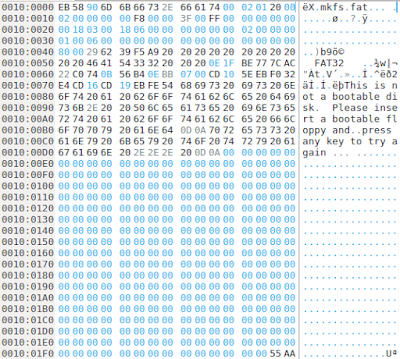
(8) The very first sector in the FAT32 partition is called boot sector. There are lots of useful information in this sector. Let's go through some of the important ones. It is a good idea to copy the first 48 bytes into a new tab in Okteta for our convenience. The information we are looking for are in this area.
 |
| First 48 bytes of the boot sector in a new Okteta tab. |
(9) In this boot sector, offset 0x0B contains 2 bytes which specify the number of bytes per sector. The value you can find in this location is 00 02 and as usual this is in little-endian. Convert it back to big-endian and you get 02 00. Converting this hexadecimal number to decimal gives us 512. That means, clearly 512 bytes per sector rule applies within this FAT32 partition.
(10) In this boot sector, offset 0x0D contains a byte which specify the number of sectors per each cluster. Let's see what is in that location. In our boot sector, this location contains the value 0x01. Converting from hexa to decimal give us 1 as the answer. That means, each cluster in this partition is actually a single sector. Simple enough.
(11) In this boot sector, offset 0x0E contains 2 bytes which specify the number of reserved sectors in this FAT32 partition. That means, the number of sectors between the beginning of the partition and the FAT1 table. The value in that offset gives us 20 00 which is in little-endian. In big-endian, we get the hexadecimal value 0x0020 which is 32 in decimal. That means, there are 32 sectors in the reserved area before the FAT1 table. It is important to note that these 32 sectors include the boot sector itself. In other words, boot sector is just another sector in the reserved area.
(12) In this boot sector, offset 0x10 contains a byte which specify the number of FAT tables we have in this partition. Usually there are 2 tables called FAT1 and FAT2, but it's better to see whether it's true. The value in that offset specify the value 02 in hexadecimal. In decimal, the value is 2 and that means we have two FAT tables indeed.
(13) In this boot sector, offset 0x11 contains 2 bytes which specify the maximum number of file entries available in the root directory. However that applies only to FAT12 and FAT16 versions of FAT. This partition that we are exploring is a FAT32 parition and in FAT32, the number of entries in the root directory is not specified here. So, we don't have to interpret anything here.
(14) The offset 0x16 in the boot sector has 2 bytes which specify the number of sectors in each FAT table. There's an important thing to note here. If these two bytes contain some non-zero value, we can take that number. However, if the location contains all zeros in those two bytes, that means, the space is not enough to specify the information. In that case, we have to go to the offset 0x24 and interpret 4 bytes there.
The value in the two bytes at offset 0x16 gives us 00 00 in our image. That means we have to go to 0x24 and take the 4 bytes it has. In our image, we have 18 06 00 00. Converting from little-endian gives us the value 00 00 06 18 which is 1560 in decimal. Therefore, we conclude that there are 1560 sectors in a FAT table. Since we have two FAT tables, they take up twice of that space.
(15) In this boot sector, offset 0x2C contains a byte which specify the first cluster of the root directory. This information is useful when we later recover file data. The value in that location is 0x02 which is 2 in decimal. That means, there are two clusters in this disk image before the root directory, namely cluster 0 and cluster 1. You will see how this information becomes useful later.
(16) Now, we have enough information to locate the root directory of this FAT32 partition. Here's how we calculate the location. The root directory is located right after the two FAT tables. That means, we just have to walk through the reserved area from the beginning of the partition, then through the FAT1 and FAT2 tables and there we find the root directory.
Offset to root directory = (number of sectors in reserved area) + (number of sectors in a FAT table) x 2
= 32 + (1560)x2
= 3152 sectors.
= 3152 x 512 bytes
= 1613824 bytes
= 0x18A000 bytes (in hex)
There's a tricky thing here. This offset specifies the location from the beginning of the partition. Unfortunately, we are dealing with an entire disk image. The FAT32 partition starts at 0x100000 bytes location as we found previously by looking at the MBR. Therefore,
Offset to the root directory (in our disk image) = 0x100000 + 0x18A000 = 0x28A000 bytes.
Let's jump to this offset in Okteta and see what we find there.
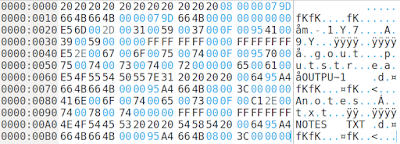 |
| Root directory of the FAT partition in a new Okteta tab. |
Yup, this location indeed looks like the root directory.
(17) Root directory contains entries which are 32 bytes long. At first glance, you can see that there are 6 entries in this root directory. For our convenience, let's copy the whole root directory to a new tab in Okteta.
(18) Now our reference document tells are which bytes in a directory entry specifies which information. The first byte of a root directory entry is important. If a file is deleted, the first byte is simply set to 0xE5. Now you can identify 3 entries which has the first byte set to 0xE5 and therefore simply deleted files. I'm going to pick just one file from this root directory and explore it. It's up to you to deal with remaining files.
(19) I'm selecting the entry at the offset 0x000000A0 to deal with. It's the last entry in our root directory. According to our reference document, first 11 bytes of a directory entry contains file name. A dot (.) is implied between the two bytes at locations 0x07 and 0x08. The values in those 11 bytes in our directory entry are as follows.
4E 4F 54 45 53 20 20 20 54 58 54
We simply have to convert each byte into the relevant ASCII character using an ASCII code chart.
NOTES.TXT
(20) In this root directory entry, the offset 0x0E contains 2 bytes which represent the file creation time. The value in that location is 95 A4 in little-endian. We convert it to big-endian to get A4 95 which is 1010010010010101 in binary. From this number, first 5 bits represent the hour. Next 6 bits represent the minute and the last 5 bits represent the seconds divided by 2.
Hour: 10100 = 20
Minute: 100100 = 36
Second: 10101 = 21 -> 21x2 = 42
Therefore, creation time = 20:36:42
(21) In this root directory entry, the offset 0x10 contains 2 bytes which represent the file creation date. The value in that location is 66 4B in little-endian. We convert it to big-endian to get 4B 66 which is 0100101101100110 in binary. From this number, first 7 bits represent the year since 1980. Next 4 bits represent the month and the last 5 bits represent the day of the month.
Year: 0100101 = 37 -> 1980+37 = 2017
Month: 1011 = 11
Day: 6
Therefore, creation date: 2017/11/06
(22) In this root directory entry, the offset 0x12 contains 2 bytes which represent the file accessed date. The value in that location is 66 4B in little-endian. That is same as the file creation date which we calculated previously. So, the accessed date is same as the created date for this file.
(23) In this root directory entry, the offset 0x16 contains 2 bytes which represent the file modified time. The value in that location is 95 A4 in little-endian. That value is similar to the file creation time. so, no need to calculate it again in this case.
(24) In this root directory entry, the offset 0x18 contains 2 bytes which represent the file modified date. The value in that location is 66 4B in little-endian. That value is similar to the file creation date. so, no need to calculate it again in this case.
(25) Now we are ready to process the the contents of the file. The location of the first cluster that belongs to this file contents is given in two fields of the root directory entry. The offset 0x14 gives the high-order 2 bytes. The offset 0x1A gives the low-order 2 bytes. Remeber that each value is in little-endian.
High order value: 00 00 -> little-endian to big-endian -> 00 00
Low-order value: 08 00 -> little-endian to big-endian -> 00 08
Cluster number = 00 00 00 08 = 8 (decimal)
Therefore, the first cluster where our file contents can be found is cluster 8.
Calculating the byte offset to the cluster number 8 is again bit tricky. This is how we handle it. In the point (15), we found that there are 2 clusters before the root directory. That means from the root directory to the file data location, there are 6 clusters because 8-2 = 6. Therefore, we can calculate to the byte offset to this file location from the root directory as follows. We simply multiply 6 clusters by the number of sectors per cluster (which is 1) and by number of bytes per sector (which is 512).
byte offset from the root directory to the file data = 6 x 1 x 512 = 3072 (decimal) = 0xC00
Now, if we add this offset to the offset of the root directory from the beginning of the disk image, we get the location of the file data exactly from the beginning of the disk image.
absolute offset to the file data = (byte offset to the root directory) + 0xC00
= 0x28A000 + 0xC00
= 0x28AC00
Now, let's goto this offset and you will see the file contents.
That's all folks!
~*************~